

執筆者: オキリョウ
最終更新: 2021/06/29
こんにちは、オキリョウと申します!
前回、Ktorの特徴について解説させていただきました。(https://oucrc.net/articles/ia_sv-bbmz)
そこで今回はKtorで重要な概念であるPipelineについて解説していきたいと思います。
Pipelineとは
Pipelineとは、Ktorにおいて処理を順序良く処理していくためのものです。
ライフサイクルを定義するためのもの、みたいな感じに考えていただけてたらと思います。
前回、Ktorには以下の特徴があるといいました。
- 拡張性が高く、柔軟
- 非同期処理に強い
これらはPipelineを導入することで実現しています。
Ktor内では、継承可能なクラスとして定義されており、そこらじゅうで使われています。Ktor内のクラスの継承元をたどっていくと一枚嚙んでいた・・・ということも珍しくありません。
それではより詳しく見ていきましょう。
Pipelineを図で表すと以下のようになります。
この画像の場合、オレンジ色の向きへと処理が流れていきます。
つまりフェーズ(Phase)1->フェーズ2->フェーズ3->フェーズ4の順番に処理が流れていくということです。
各フェーズ同士は依存していません。しかし、共有する必要のある値ももちろん存在します。
それらはPipelineが所有しているPipelineContextに保存しておき、そこから値を取り出す仕組みになっています。
また、フェーズは好きなところに付け足すことも可能です。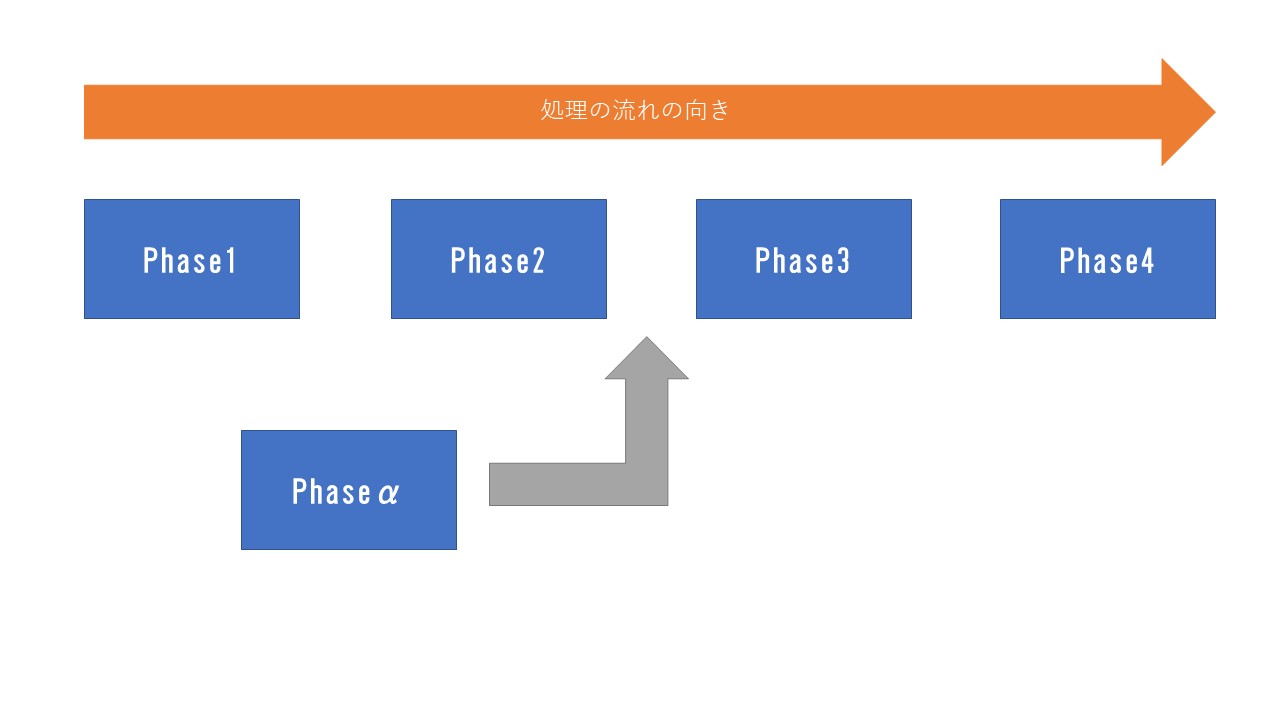
このように、左から右へと、それぞれ独立したフェーズを処理していく流れがPipelineです。
Pipelineの使用例
では、Pipelineがどのように使われているのか見てみましょう。
例えば、サーバーサイドアプリケーションの中でも必須である、「リクエストを受けとってリスポンスを返す」という部分はPipelineで実装されています。(ApplicationCallPipelineという名前のクラスです)
このオレンジ色の矢印がApplicationCallPipelineです。
こんな感じに差し込まれています。
リクエストを受けとって、そこから各フェーズを実行してリスポンスを作成、返すという感じです。
ではより具体的に見ていきましょう。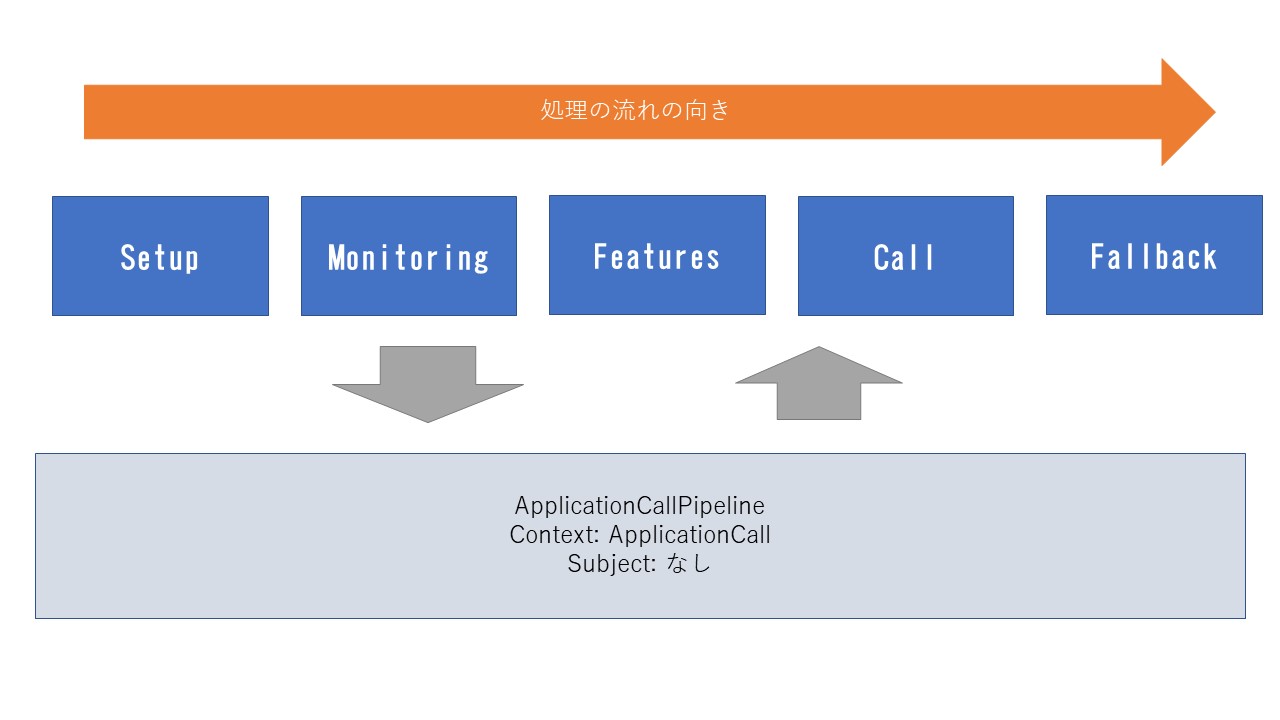
このような感じになっています。
左から順番にSetup -> Monitoring -> Features -> Call -> Fallbackの順番に処理が流れています。これら青い部分がフェーズですね。
これらのフェーズの役割は以下の通りです
Setup: callやattributesを用意する
Monitoring: callを追跡するための部分で、ログやコードの評価を行う、エラーハンドリングなどに使われる
Feature: 大体のFeatureが入るところ
Call: callを完全に作りきるために利用するところ
Fallback: ハンドリングされていないcallを何らかの形で処理する部分
補足
call:ApplicationCallの事。リスポンスであったりattributesであったりを管理している
attributes:DIコンテナ(多分、詳しく知りたい人は公式をチェック)
Feature:Ktorの追加機能の事。後述
それぞれのフェーズを順に通していく中で徐々にリスポンスを作成しています。
この流れがPipelineです。
ちなみにRouting等もPipelineを使用しています。
ではPipelineについてある程度説明したところで
- 拡張性が高く、柔軟
- 非同期処理に強い
を実現している方法について説明していきたいと思います。
拡張性が高く柔軟
Pipelineはそれぞれのフェーズを定められた順に実行していくことは先ほどまで書いた通りです。
また、これらのフェーズは互いに依存しておらず、好きなところに差し込むことができるということも説明したと思います。
必要なフェーズを差し込んだり、要らないフェーズを抜くことができるということは、必要な処理だけを記述することができるということです。
それに加えて、実はフェーズの間に処理を入れることも可能です。(intercept)
先ほどちらっと登場したFeatureというのは、このような処理を練りこんだライブラリといえます。
そのようにすることで、本来複雑になるはずのライブラリの作成、導入が非常にシンプルにできるわけです。
せっかくですので、リスポンスのヘッダーに現在時刻を付ける、というFeatureを定義、導入したコードを掲載します。
まずは現在時刻を付けるFeatureの定義から
package com.example
import io.ktor.application.*
import io.ktor.response.*
import io.ktor.util.*
import io.ktor.util.pipeline.*
import java.time.LocalDateTime
class SendTimeHeader(configuration: Configuration) {
private val name = configuration.headerName
//設定
//この場合、ヘッダーのkeyの部分を設定できるようにする
class Configuration{
var headerName: String = "Send-Time"
}
//差し込まれる処理
private fun intercept(context: PipelineContext<Unit, ApplicationCall>){
//設定された値と、現在時刻をheaderにセット
context.call.response.header(name, LocalDateTime.now())
}
//アプリケーション実行時に行われる処理
companion object Feature : ApplicationFeature<ApplicationCallPipeline, Configuration, SendTimeHeader>{
//Attributeを設定
override val key: AttributeKey<SendTimeHeader> = AttributeKey("SendTimeHeader")
//install時の処理
override fun install(pipeline: ApplicationCallPipeline, configure: Configuration.() -> Unit): SendTimeHeader {
val configuration = Configuration().apply(configure)
//インスタンスの作成
val feature = SendTimeHeader(configuration)
//ApplicationCallPipelineのCallというフェーズに以下の処理を入れる
pipeline.intercept(ApplicationCallPipeline.Call){
//先ほど定義した、interceptの処理
feature.intercept(this)
}
return feature
}
}
}
こんな感じです。
非常に見づらくなってしまい申し訳ないですが、雰囲気は理解できたかと思います。
実装の流れはそのうち別の記事で説明すると思います。
ちなみに今回の場合は、ApplicationCallPipeline↓
のCallのところにこちらの処理が入ります。
それでは利用するときのコードも掲載します
package com.example
import io.ktor.application.*
import io.ktor.response.*
import io.ktor.routing.*
import io.ktor.util.*
import io.ktor.util.pipeline.*
import kotlinx.coroutines.launch
fun main(args: Array<String>) = io.ktor.server.netty.EngineMain.main(args)
fun Application.main(){
//先ほどのFeatureの導入
install(SendTimeHeader){
headerName = "Time"
}
routing {
//ホームルートにアクセスしたときに「Hello World」を返す
get("/"){
call.respondText("Hello World")
}
}
}
これだけですね。
installのところでFeatureを指定(必要ならば設定も行う)するだけで、すべてのルートにて、現在時刻が追加で刻まれたヘッダーが返却されます。
一見複雑に見えるかもしれませんが、普段は利用するだけ、つまり下側だけですので非常にシンプルです。
上側の方も、やっていることはそこまで複雑ではなく、他のフレームワークで同じことをすることを考えたらはるかに簡単だと思います。
他にも認証機能やログを取る機能もこんな感じで簡単に導入できます。
このように、簡単にいろいろなライブラリを導入したり、作成したりすることができます。
ですので、自分が好きなライブラリで固めることも可能ですし、かなり規模の大きいアプリケーションを作成することも全然可能です。
これもPipelineだからできることです。
非同期処理に強い
前回、KtorではCoroutineというものを使い倒しており、そのために非同期処理に強いという話を書きました。
Pipelineもこの流れを強く受けています。というのも、PipelineContextはCoroutine Scopeを継承しており、Coroutine Scopeとして扱うことができるためです。
例えば
routing {
//ホームルートにアクセスしたときに「Hello World」を返す
get("/"){
launch{
TODO("Coroutineを起動")
}
}
}
という感じで、さらっとCoroutine builderを呼び出すことができます。
get()関数は引数としてPipelineContextを取るからですね。
このように、わざわざCoroutine Scopeを定義する必要もないため、気軽に非同期処理を書くことができます。
また、非同期処理が強い理由としてProceed関数およびProceedWith関数の存在もあります。
ややこしい説明になりますが、この関数を実行したインターセプター(フェーズの間に入れる処理群の事)の処理は後回しにされます。
なんの役に立つのかと思うかもしれませんが、意外と使えます。
例えばかなり重たい処理があったとします。その時はPipelineと違うCoroutineを立ち上げて、その後Proceed関数を実行します。
本来だとCoroutineを立ち上げた場合は、そのCoroutineの処理が終わるまで待機しないといけないため、Coroutineの処理が長ければ長いほどレスポンスが遅くなります。
しかし、後回しにすることで、かなり重たい処理とほかの処理を並列に実行することができます。
重たい処理の完了を待つことなく別の処理を進めることができるため、早く処理を終わらすことができるというわけです。
このようにPipelineを用いることで、非同期処理を簡単に、しかし効果的に書き上げることができるのです。
他にもPipelineではCoroutineを生かして処理の効率化を図っていますが、ここでは省略しています。
まとめ
いかがだったでしょうか?ちょっと説明が難しくなってしまい、申し訳ございません。
ただ、このフレームワークはかなり面白いので、実際に組んでみる価値は大いにあります。
また、公式がより分かりやすく説明してくれています(英語ですが)
ぜひそちらの方にも目を通してみてください!
あと、ここまでの説明は公式の解説と、コードを読んでみた結果から書いています。
何かしら間違っていたら申し訳ございません。

2020年度 入部
この人が書いた記事





