

執筆者: 瀕死
最終更新: 2025/09/29
概要
オリジナルのプログラミング言語 namep を開発したので紹介する.
経緯
2025年の春休みに部内では空前の自作言語ブーム(諸説あり)が巻き起こっていた. それに便乗して自分でも言語を作ってみようと思いつつも,面倒なので何もしていなかった. ところが,2年1学期の講義に"プログラミング演習"というものがあるのだが,ここではC言語でCLIの名簿管理プログラムを作成するということが分かった. それなら,この課題の独自機能として自作言語を統合しようということで実装された.
この講義で誕生した言語がnamepである. 名前の由来は,NAME table Processorから来ている.
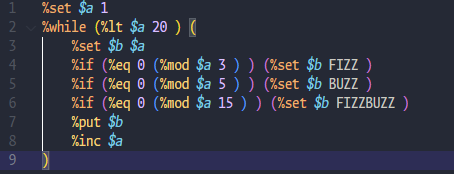
FizzBuzzをとりあえず
入力が対応していないので1行で入力してください.
プレイグラウンド: https://hinshiba.net/namep/
%set $a 1
%while (%lt $a 20 ) (
%set $b $a
%if (%eq 0 (%mod $a 3 ) ) (%set $b FIZZ )
%if (%eq 0 (%mod $a 5 ) ) (%set $b BUZZ )
%if (%eq 0 (%mod $a 15 ) ) (%set $b FIZZBUZZ )
%put $b
%inc $a
)
講義による制約
これは講義の製作物として提出する必要があったので,仕様の範囲内で作成する必要があった. 具体的には次の3つである.
- C言語で作成する
- 標準ライブラリのみ用いる
- 講義の提出日までに完成する このことから簡単に解析できそうなLL(1)文法にすることとした.
また,満たすべき入力の仕様として次のようなものがあった.
- コマンド
%C,%P -1,%F 2025-1-12,%F hoge huga%とASCII文字1つで構成されるコマンド種別- コマンドごとの引数
- 名簿
000, hinshi ba,2025-1-12, ADRESS, remarks place- ID, 固定長文字列, 日付, 固定長文字列, 任意長文字列をコンマ区切りにしたもの
このことから, よって講義の製作物テストの入力仕様をクリアしつつ,独自言語の入力を受け付ける必要があった.
大まかな構文を決めよう
元の仕様をできるだけ自然に拡張したかったので,関数もコマンドとして%から始まるものとした. プログラミング言語のようにコマンドを扱う第一歩として,次のような2つの構文をまずはサポートすることとした.
- 順次実行: C言語風に書くと
%C(); %P(0); %Q(); - 引数の評価: C言語風に書くと
%P(%C);
まず,仕様上の入力%P 0のように()で引数を囲むことができないから,()を消去して
- 順次実行:
%C; %P 0; %Q; - 引数の評価:
%P %C;
となり,仕様上の入力からコマンドの終端に文字を配置できないので,;を消去して
- 順次実行:
%C %P 0 %Q - 引数の評価:
%P %C
となる.これでは順次実行なのか引数なのか判断できないことになってしまう.
妥協として,コマンドの引数にコマンドを渡すときのみ()をつけるものとした.
- 引数の評価:
%P (%C)*注: これは現在はエラー
その後のなんやかんやのうち,構文として次のようなものを作成した.
<input> ::= <cmds> | <csvrecord>
<csvrecord> ::= <int> "," <str> "," <date> "," <str> "," [<str>]
<cmds> ::= <cmd> +
<cmd> ::= <cmdname> (<str> | <int> | <date> | <val> | "(" <cmds> ")" )*
字句解析について考える
まず最初に問題となったのは,一般的な文字列に"を付けられないことである. 具体的には%hoge a b cがa bとcを引数に渡したのかaとb cを引数に渡したのか不明になるという問題が生じる. 最も問題となったのは,標準の検索コマンド%Fで%F hinshi baや%F remarks placeのように,空白の数を保持する必要がある. これもまた妥協として,%Fは任意長引数をとれるものとし,受け取った引数を1つのスペースで結合するものとした. 複数のスペースはテストケースになかったので,その入力は"で囲まなければならないと仕様書に記述してごまかした.
よって文字列は次の2つのいずれかということになった.
- 次の要件をすべて満たすエスケープ不要な文字列
- 特殊な意味をもつ文字
,,%,$,(,)を含まない - 数字のみで構成されない
0から始まるならば,0でない文字列- 日付として解釈される文字列のみで構成されない
- 先頭に入力を意図した空白文字がない
%Fの引数ならば,一つの半角スペースのみ引数の間にあると仮定できる
- 特殊な意味をもつ文字
"で囲まれた文字列
また,名簿入力時は先頭の空白以外は読み捨てないこととしている.
数値については深く考えず,基本的にはstrtol()を呼んでみて次の文字が区切りなら<int>,-なら日付,該当しなければ文字列ということにした. 面倒なのと実用例が思いつかなかったので小数は扱わないものとした.
コマンド名は%の後を文字列として解析しているので,%hoge)とするとまずいので,%hoge )と書くという仕様にした.
変数は$から始まる文字列ということにした.これについては特に難しい処理はなかった.
実装について
字句解析は難しいことは全く行っていないが,仕様の複雑さから,ifとネストから脱出をするためのgotoでスパゲッティコードになっている.担当する関数の循環的複雑度をlizardで評価したところ,2828という他の関数に比べて異様に大きな値が出ている.
名簿入力なのかを判定するために,字句解析の段階で先読みが行われているなどかなり適当な実装となっている.
/**
* @fn
* @brief 文字列 lineをトークンの連結リストにする
* @return 先頭トークン
* @details
*/
Token *tokenize(const char *line) {
/// 先頭トークンを指すための空のトークン
Token head;
head.next = NULL;
Token *current = &head;
/// cmdsかどうか記憶する.(CSVが空白関連でかなり厄介なため)
int is_cmds;
/// lineのsub
const char *p = line;
/// select_int()の結果格納先
int num;
/// Data型かどうかの一時記録
Date date;
/// select_int()でどれぐらいポインタを進めるか
const char *next;
/* 最初のトークンがcmdnameになりそうか調べる */
while (*p) {
if (isblank(*p)) {
++p;
continue;
} else {
is_cmds = (*p == CMD_START);
break;
}
}
// printf("torknizer mode: %d\n", is_cmds);
while (*line) {
/* 空白は読み飛ばす */
if (isblank(*line)) {
++line;
continue;
}
/* ------------------中略------------------- */
/* 0処理 */
/* 00, 01は文字列にするが,0は数値にしたい */
if (*line == '0') {
if (*(line + 1) != CSV_SEP && !isblank(*(line + 1)) &&
*(line + 1) != '\0') {
goto str;
}
}
/* 数値処理 */
if (isdigit(*line) || *line == '-' || *line == '+') {
next = select_int(line, &num);
if ((isblank(*next) || *next == '\0') && is_cmds) {
/* 数値に変換成功 cmd */
current = add_token(TK_INT, current);
current->num = num;
line = next;
continue;
} else if ((*next == CSV_SEP || *next == '\0') && !is_cmds) {
/* 数値に変換成功 csv */
current = add_token(TK_INT, current);
current->num = num;
line = next;
continue;
} else if (*next == DATE_SEP && is_year(num)) {
/* Date型疑い */
date.y = num;
/* ------------------中略------------------- */
/* うまくいけばcontinueしているはずなのでstrに行く */
} else {
/* 文字列扱い なにもしない */
}
}
str:
/* 文字列 */
current = add_token(TK_STR, current);
current->str = select_str(&line, !is_cmds);
}
/* parserでNULL refしないため */
current = add_token(TK_EOT, current);
return head.next;
}
一方で,構文解析についてはLL(1)文法なので,再起下降構文解析法を用いれば簡単に手書きでパーサーが実装できる.
/* ------------------前略------------------- */
/**
* @fn
* @brief cmdsを解析する
* @param token: tokenの連結リスト
* @return AST
* @details <cmds> ::= <cmd>+
*/
Node *parse_cmds(Token **token) {
Node *node = create_node(ND_CMDS);
do {
add_child(node, parse_cmd(token));
} while ((*token)->kind != TK_EOT && (*token)->kind != TK_RPAREN &&
isnode_noerror(node));
return node;
}
/**
* @fn
* @brief csvrecordを解析する
* @param token: tokenの連結リスト
* @return AST
* @details <csvrecord> ::= <int> "," <str> "," <date> "," <str> "," [<str>]
*/
Node *parse_csvrecord(Token **token) {
Node *node = create_node(ND_CSVRECORD);
/* ID */
add_child(node, consume_int(token));
node->error += expect(token, TK_SEP);
/* Name */
add_child(node, consume_str(token));
node->error += expect(token, TK_SEP);
/* Date */
add_child(node, consume_date(token));
node->error += expect(token, TK_SEP);
/* Addr */
add_child(node, consume_str(token));
node->error += expect(token, TK_SEP);
/* Remarks */
if ((*token)->kind == TK_STR) {
add_child(node, consume_str(token));
}
return node;
}
/**
* @fn
* @brief 読み込んだ行を処理をする
* @param token: tokenの連結リスト
* @return AST
* @details <input> ::= <cmds> | <csvrecord>
*/
Node *parse_input(Token *token) {
Node *node = create_node(ND_INPUT);
if (token->kind == TK_CMDNAME) {
add_child(node, parse_cmds(&token));
} else if (token->kind == TK_INT) {
add_child(node, parse_csvrecord(&token));
} else {
node->error += 1;
fprintf(stderr, "error in parse_input\n");
fprintf(stderr, "first token is not valid\n");
}
/* eotまで読めてないならエラー */
if (token->kind != TK_EOT) node->error += 1;
if (node->error) {
fprintf(stderr, "error in parse_NODE somewhere\n");
}
return node;
}
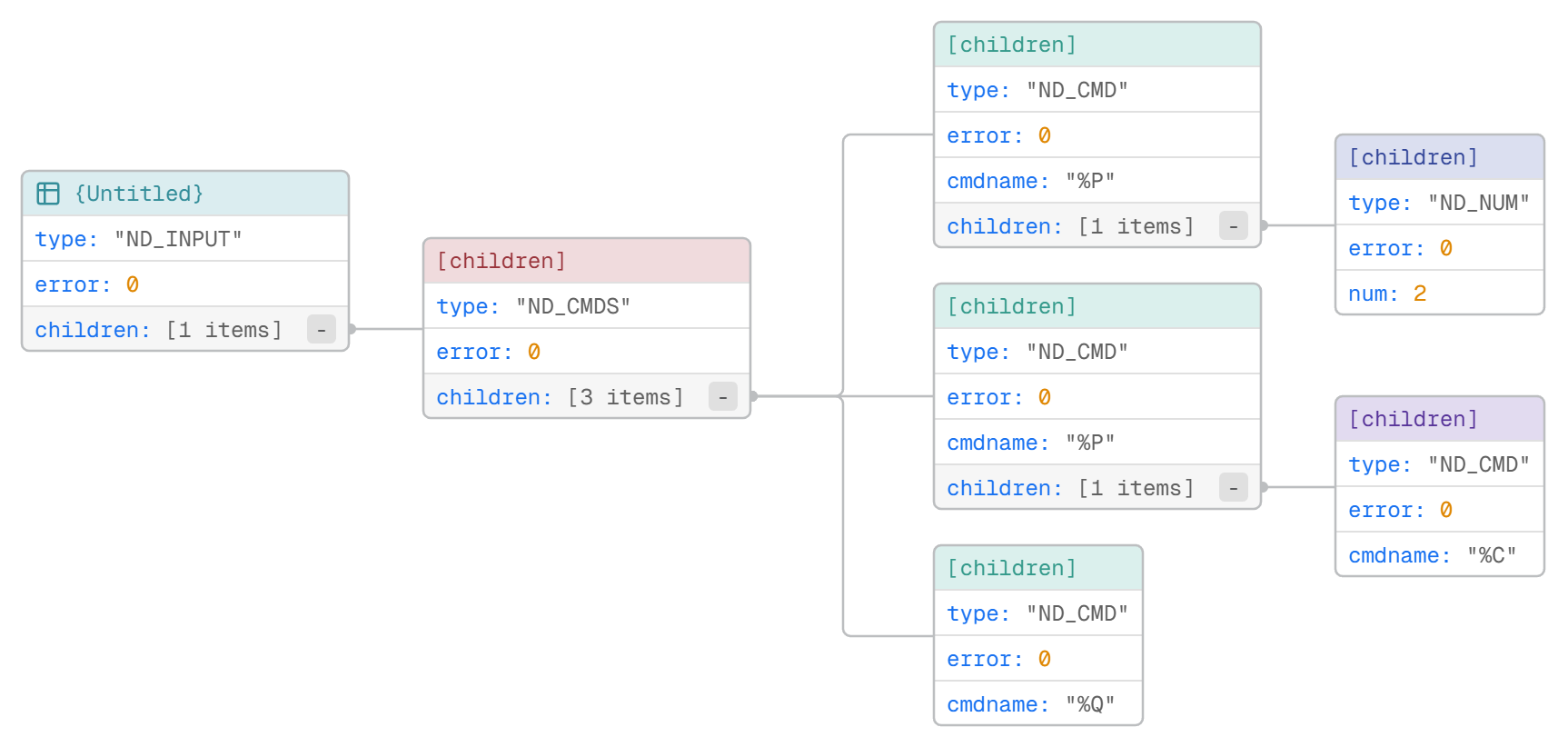
これによって次のようなASTが得られる.
VSCodeの拡張機能
自分が書くのもかなり大変なので,VSCode向けに拡張機能を作成した. ハイライトされるのでかなり使いやすくなるが,現時点では非公開である.そのうち公開したい.
プレイグラウンド
実は実行環境をインストールしなくてもプレイグラウンドを作成している. この実装については別の記事を作成する予定である.
ハイライトはないです.
実用例
これを友人に話したところ,実用性が皆無だとか言われたので実用?例を示す.
IDが51178295117829より小さい人の名簿を消去する.
%set $i 0
%while (%lt $i (%tnum ) ) (
%set $id (%tget $i 1 )
%if (%lt $id 5117829 ) (
%tdel $i
)
%if (%lt 5117829 $id ) (
%inc $i
)
%if (%eq 5117829 $id ) (
%inc $i
)
)
%gtや%ge,%elseのような便利なコマンドは存在しません.
あとがき
プレイグラウンドはあるのに,ドキュメントと実行環境は公開されていません. これもそのうち......
明らかに講義のプログラミングを舐めているので舐めたプログラミングからnamepというネタもあります

2024年度 入部
この人が書いた記事







